“You can decorate absence however you want – but you’re still gonna feel what’s missing.” – Siobhan Vivian, Same Difference
In a previous post, we identified “missing data” as one of 4 data collection mistakes to avoid. We also made some suggestions on how to deal with information that is not available. With particular reference to electronic data collection, we pointed out that researchers should generally not allow missing responses. Instead, they should only allow for them. In other words, an enumerator should not be able to go through a question without providing input, even if only to say that the data is missing.
For text and numeric fields, the convention is to use placeholders to represent missing values. Common placeholders include “99”, “999”, “9999” and so on. The problem with placeholders like these is that computers, by default, infer meaning and run analysis on them.
Say for example you interview 5 people and ask for their age. The first person reports his age as 20, the second as 25, the third as 30, the fourth as 20 and the fifth as unknown. If you are using “999” as the placeholder for unknown age, your dataset becomes [20, 25, 30, 20, 999] with n = 5. Now, if you run the average on these numbers, the result is 218.8 years, which is obviously misleading because it is unduly skewed by the placeholder value of 999.
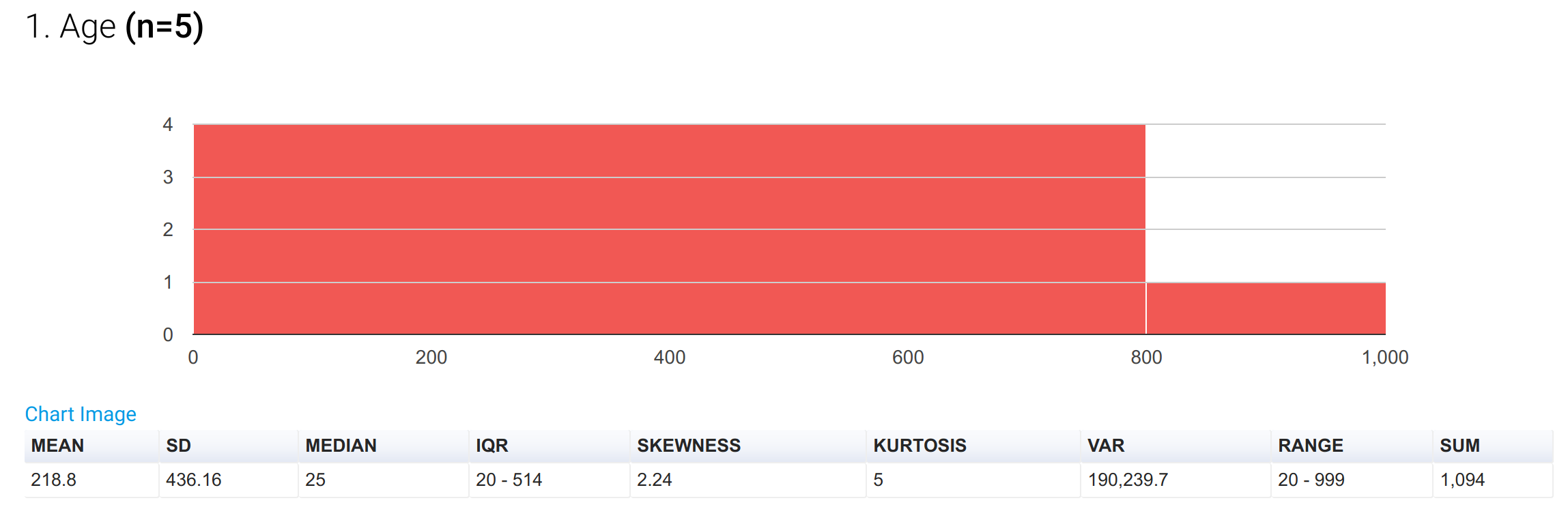
Fig 1:A histogram and summary statistics, with 999 treated as a valid value.
Hoji has previously avoided this problem by advising survey designers to ask for age conditional on a Yes/No question that asks if the respondent knows their age. This yields the dataset [20, 25, 30, 20] with n = 4. If you run the average, the correct result of 23.5 years is obtained. But although this works, it is also a bit cumbersome because it requires the researcher to insert an extra question.
The new version of Hoji now allows missing values to be handled more simply and cleanly. Instead of adding a new question, the researcher merely specifies, in a comma-separated list, the value or values he wishes to use to represent missing values. So in the question of age, for example, you might specify “999” or even “999, 9999” to accommodate two different flavors of the missing value placeholder.
This achieves the following.
Firstly, it requires that the enumerator enter the value “999”, preventing him from erroneously swiping past the question without providing input. Secondly, the value 999 is exempted from validation logic. For instance, if age is validated to between 1 and 100 years, the value 999 is still acceptable and it not rejected as being “out of range” during data entry. Thirdly, Hoji’s data analysis engine treats the value 999 exactly as it would a null value, meaning it exempts it from analysis so that it does not skew the results abnormally.
With this implementation, the original dataset effectively changes to [20, 25, 30, 20, Missing] with n = 5 and Missing = 1. Summary statistics are ran only against the the substantive values, and thus yield the correct results.
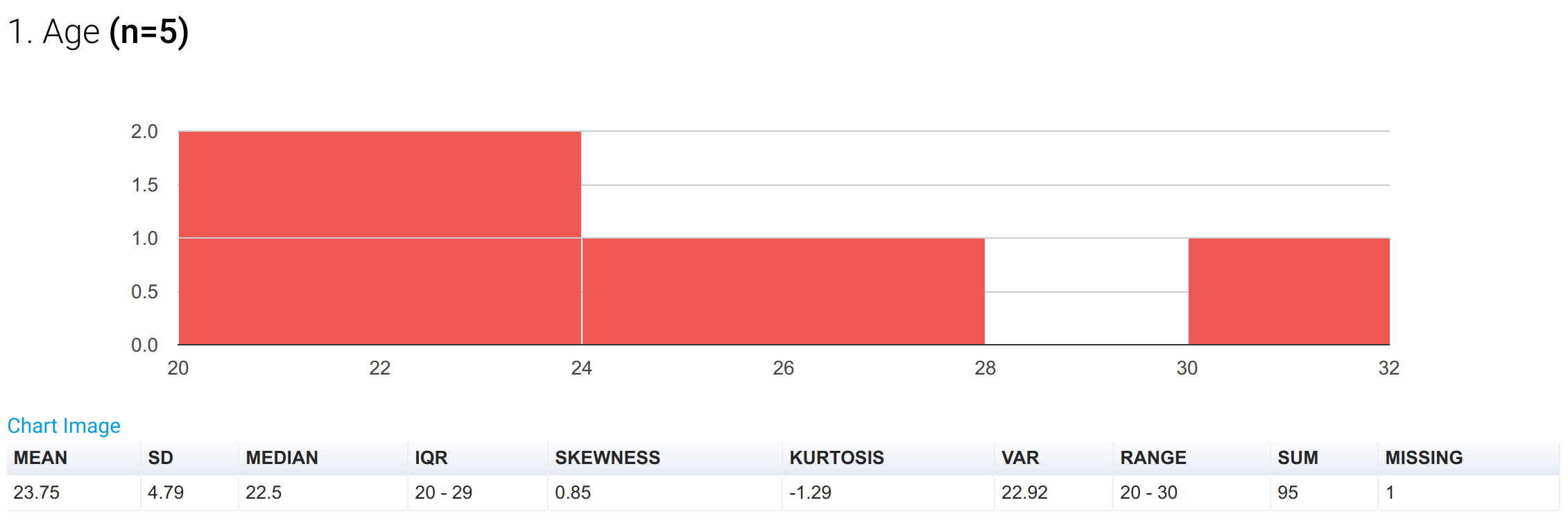
Fig 2: A histogram and summary statistics, with 999 treated as a missing value.
As a bonus, this feature is 100% backwards compatible. So if you have an old dataset on Hoji that used one or more placeholder values, all you need to do is go and specify that value against the relevant field and Hoji will recalculate all your summary statistics accordingly.
Test