“Prevention is better than cure.” – Proverb
Do you spend days cleaning your survey data at the end of the data collection process? Well, you might want to rethink your approach. Now, don’t get me wrong. There are many datasets for which it makes perfect sense to perform data cleaning. Survey data just isn’t one of them. Certainly not in 2020!

Data obtained from secondary sources that you have no control over often has gaps and inconsistencies that you must identify and correct before analysis. Similarly, data entered from paper forms into a spreadsheet or some other database is bound to have transcription errors and other problems that can only be addressed through data cleansing.
With survey data, however, you almost always have full control over the sampling, tools and processes involved. This provides a unique opportunity to implement robust mechanisms for gathering high quality data from the get go, thereby all but eliminating the need for cleaning. Of course, this is only possible with digital and not pen and paper data collection.
Good quality data
The goal of data cleaning is to obtain good quality data. Good quality data is defined by its validity, completeness, consistency, uniformity and accuracy. Data cleaning generally deals with the first four of these elements. Accuracy is impossible to verify without access to the original data source – which analysts rarely have. If a respondent’s age was recorded as 35 years, for example, the only way to verify it is to find the respondent and ask for proof.
Let’s examine each of the four elements above and discuss how you can collect high quality data and eliminate or reduce the need for cleaning.
Validity
Data validity refers to the extent to which a piece of data corresponds to its meaning in the real world. For instance, the response to the variable Age cannot be Male, nor can the response to the variable Sex be 35. Similarly, a telephone number cannot be one digit long or contain alphabetical letters.
Nearly all electronic data collection applications allow you to limit unreasonable data by implementing constraints. Constraints are rules that restrict the kind of data that can be accepted by the system. There are various types of constraints, such as data type constraints, mandatory constraints, range constraints, unique constraints, regular expressions and cross-field validation.
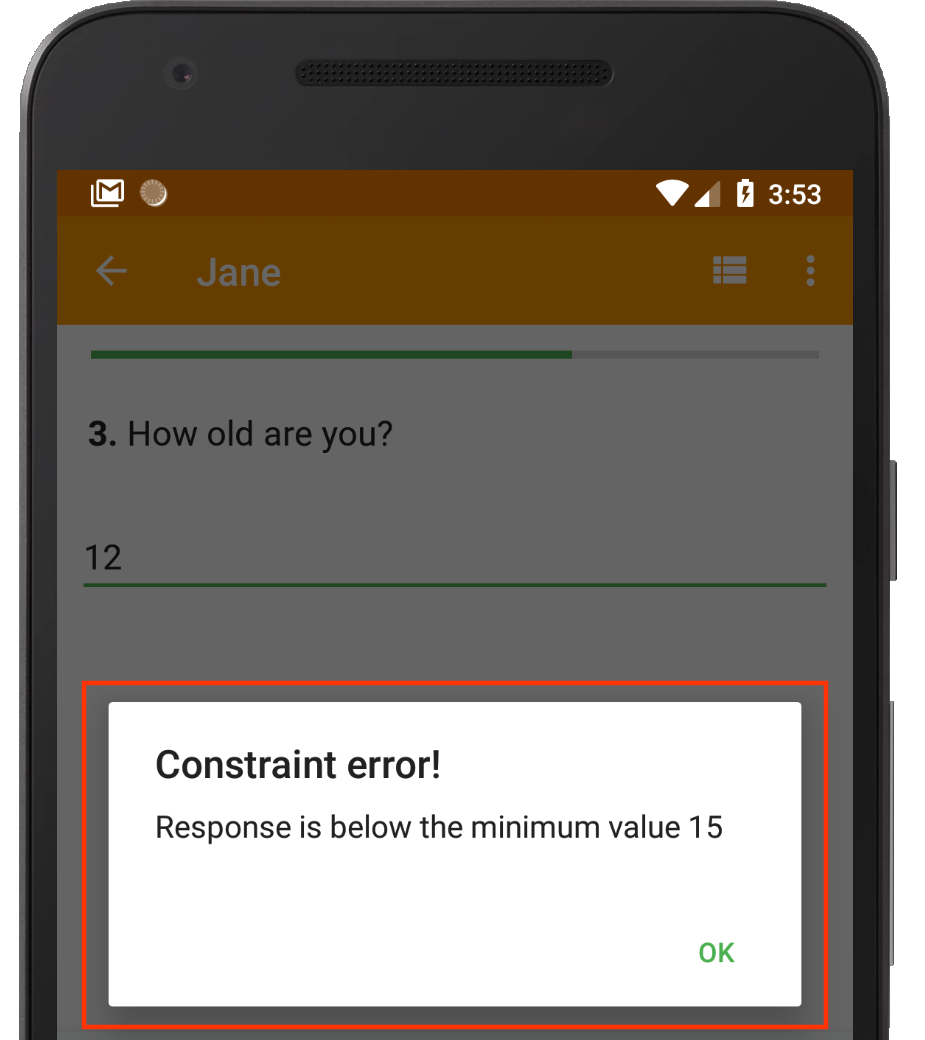
Range constraint in action.
By keenly implementing the necessary constraints within your digital data collection tools, you can ensure that only valid data makes it to the study database.
Completeness
Data completeness refers to the extent to which all required data is present in the dataset. For example, the response to the question Do you smoke? should not be null. A null value would be difficult to interpret during analysis. Would it mean that the enumerator forgot to ask the question or that the respondent refused to answer it?
Often, it is best to require that all survey questions are answered. In most electronic data collection systems, this requires setting up a “mandatory constraint”. A mandatory constraint eliminates the possibility of the enumerator inadvertently skipping over any of the questions.
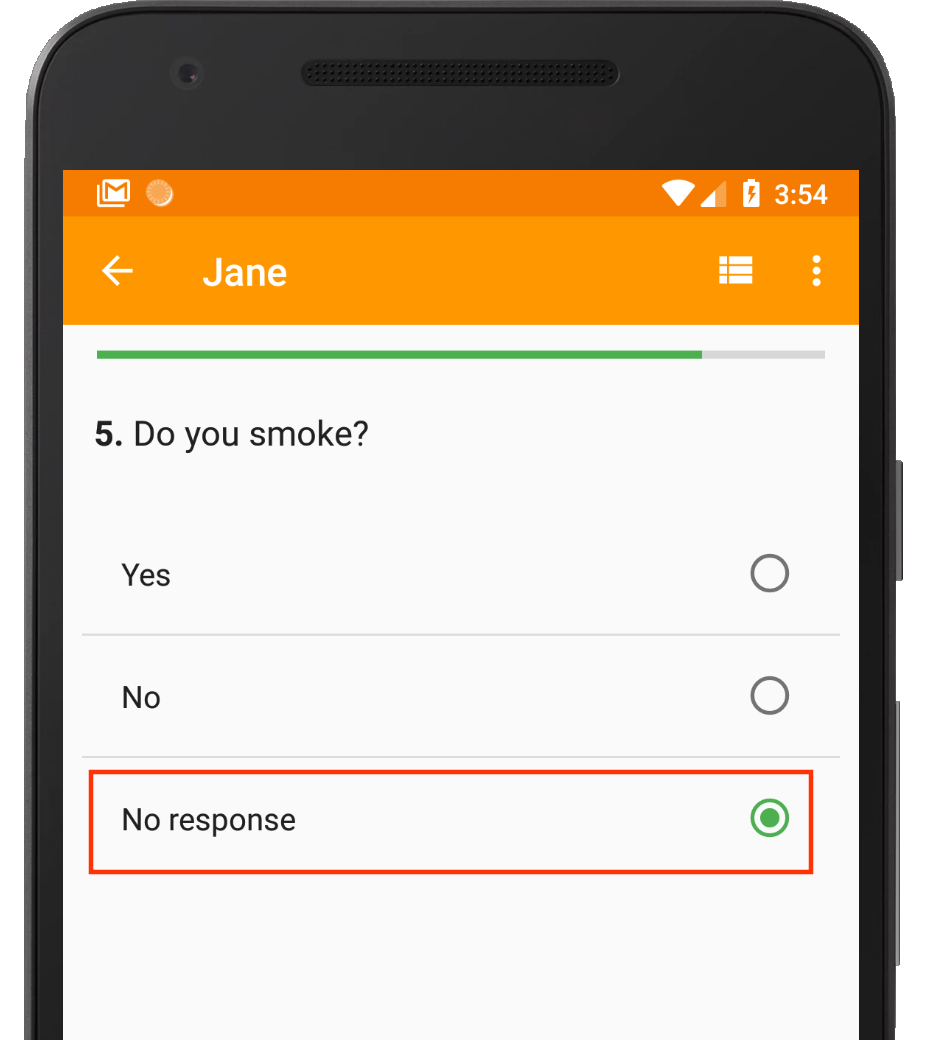
A “No response” option allows the enumerator to explicitly record “missingness”.
However, in order for mandatory constraints to work, you must also provide some means for the enumerator to – excuse the oxymoron – capture missing data. For categorical data where a respondent is supposed to choose from a list of options, you could include additional choices such as Don’t know or No response. For numeric data such as Age, you could add an instruction like If unknown, please enter 999.
Consistency
Data consistency refers to the extent to which data does not contradict itself. For example, if a respondent is male, then we do not expect to see that he is 6 months pregnant – or pregnant at all, for that matter! Similarly, if a respondent doesn’t smoke, we don’t expect to see that he smokes 10 cigarette sticks per day.
In surveys, data consistency problems can be forestalled through the appropriate use of skip logic. Skip logic is sometimes referred to as branching logic or skip patterns. It refers to the means by which you can filter out the questions posed to a respondent based on their responses to previous questions. For example, once a respondent states that they are male, any questions regarding their pregnancy status should automatically be skipped.
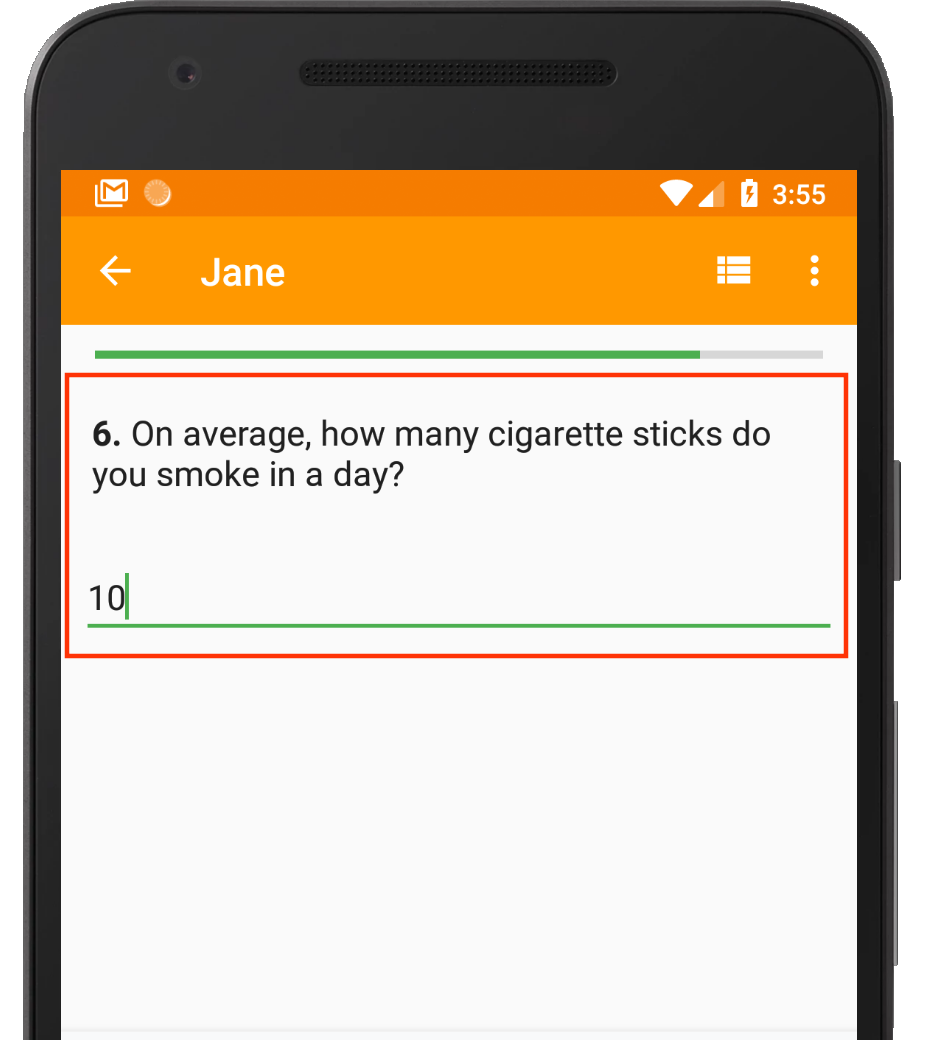
Skip logic ensures that this question is only asked if the respondent says they smoke.
By implementing skip logic, you can ensure that your enumerators do not pose irrelevant questions to respondents, thus eliminating data consistency issues before they happen.
Uniformity
Data uniformity refers to the extent to which data that measures the same quantity can be compared directly. Take height data, for example. In order to analyze and compare it across respondents, it must be expressed in the same units e.g. meters or centimeters.
Obvious as it may sound, many questionnaires fail to explicitly specify the units in which a particular quantity should be expressed. This results in unnecessary misery and guesswork during data analysis.
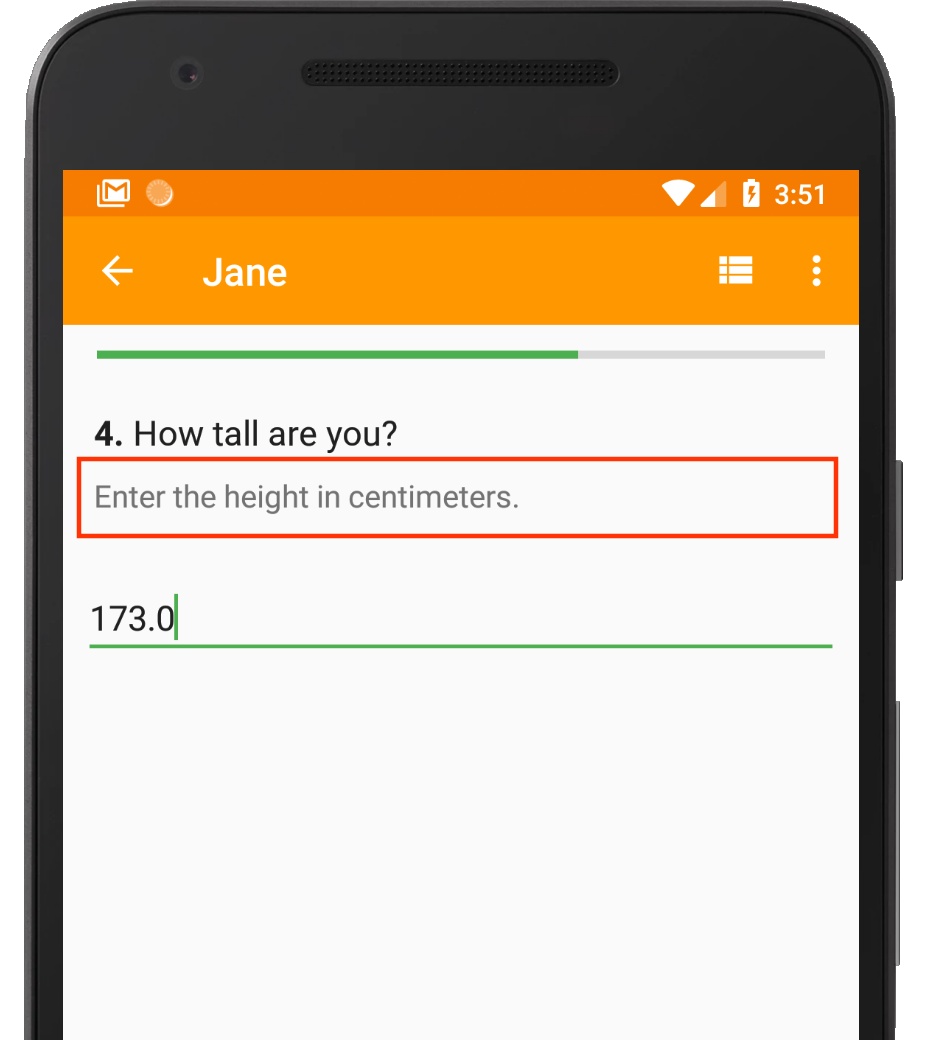
This instruction explicitly tells the enumerator what unit of measurement to use for height.
Sometimes, it is not possible to use one unit of measurement without requiring enumerators to perform complex mental conversions. Such may be the case with, say, converting from Celsius to Fahrenheit or between currencies. In these cases, an alternative approach is to provide a second variable for unit of measure. This allows the enumerator to select the unit of measure in which the quantity entered is expressed. Conversion can then be deferred until the data analysis stage where it can be easily automated.
Conclusion
By carefully considering these data quality elements and proactively configuring your digital data collection tools to uphold them, you can eliminate all or almost all of the need for data cleaning. This frees up your time to perform the more critical work of data analysis, results interpretation and decision making.
What’s your experience with cleaning survey data? Share your thoughts in the comments section below.
Thank you for this great post. I always look forward to them.
You’re welcome. We’re always happy to share and learn from others.
This is a niece piece- even more painful than data cleaning is having to discard data because it is unusable due to the way it was collected. Preventing collection of “crap” in the first place is a pleasant safeguard!
Absolutely!
This is great piece of work. Indeed if all those aspects are considered then the need of data cleaning will be greatly educed. Installing High Frequency checks can also be good way of establishing possible errors early enough for validation
I agree. Monitoring the data on an ongoing basis allows the researcher to catch and address anomalies in good time. Thanks for sharing the tip!
Insightful. Prevention is better than cure indeed.
true statement thank you
This is just timely at the time am in the last phase of endlline data collection. Thank you for this insightful note.
You’re welcome. Glad you found it helpful.
This is a brilliant post Gitahi.
Thanks.