When we say we take your feedback seriously, we mean it.
One of the major features we’ve had clients consistently request for is support for longitudinal data collection. The problem sounds deceptively simple, but it has eluded mobile data collection solution providers for a long time.
Part of the issue is that many longitudinal studies whose needs appear markedly different aren’t really that distinct. Not from a software standpoint anyway, and treating them as if they were causes unnecessary complications. Bold claim, I know, but hear me out.
The problem
In nearly all cases, the problem boils down to this: You collect some baseline data, typically on enrollment to the study. Then, you periodically collect follow-up data thereafter. There may be auxiliary requirements such as sending SMS reminders and so on but, the crux of the problem doesn’t vary much.
In a perfect world, each participant would be enrolled at the same site by the same field worker on the same mobile device. They would also come back for follow-up at that same site and be seen by the same field worker using the same device. All the data you need in one place. Not hard to do. Happiness.
In the real world, these assumptions are hardly realistic. Firstly, participants will enroll and report for follow-up where they may. As the project director, you have no control over that. Secondly, field workers will join and leave your project from time to time. Again, zero control over that. Thirdly, mobile devices will break down or get lost, taking with them all the data stored therein. No control over that either.
All doom and gloom? Not anymore.
Problem evaporated
At Hoji, we’ve developed a general purpose solution to this problem, and it works for all situations that fit the classical enrollment-follow-up mold. We call it distributed longitudinal data collection. Why distributed? Because we make zero assumptions about the location of participants or the identity of field workers and mobile devices used in the study. Our solution allows participants to be enrolled and followed up at any location by any field worker on any mobile device at any time, making your study data virtually ubiquitous across the platform. Problem evaporated.
Two way synchronization
How do we do this?
There are two critical components to our distributed longitudinal data collection solution. Firstly, Hoji fully supports two-way data synchronization. Literally every mobile data collection application in the market today lets you upload data to a server. Few, if any, let you do the reverse. Our mobile app allows field workers to find and import existing records from the server onto their devices, see historical visits and enter new follow-up data or otherwise make any necessary modifications.
Participant identification
Secondly, in order to import data from the server, there must exist a reliable and accurate means by which to retrieve participants’ records. This is doubly important in healthcare where mixing up patient information could lead to catastrophic results. Most projects solve this problem by assigning unique Study IDs to participants. This is a reasonable solution, except it makes the not-so-realistic assumption that participants will bring their Study ID cards or memorize their numbers.
Our strategy involves not only letting projects automatically assign universally unique Study IDs but also collect up to 5 additional identifiers mapped to the Study ID. Notice that we do not call these additional identifiers unique. They need only be “unique enough”, meaning that a) they must be not be shared by more than a few participants and b) taken together they are either unique or reasonably close.
These additional identifiers can vary from “trully unique” alternatives such as National ID and Telephone numbers to far “roughly unique” ones like the names of the participants’ themselves or even of the sites where they enrolled. While participants can easily forget their study IDs, nobody forgets their name. Similarly, few people forget their National ID numbers, and fewer still their Telephone numbers. Most participants can also be expected to remember their enrollment sites.
The powerful thing about this strategy is that field workers, through the Hoji mobile app, can look up a participant’s record using any of the designated identifiers. More importantly, any record retrieved through any of these identifiers includes the rest of the available identifiers as well, making the problem of identity resolution as simple as the field worker asking, “You said your telephone number is 712 345 678. What is your name?”. Immediately, the field worker can distinguish between the 3 or 4 members of the same family or neighborhood enrolled under that telephone number.
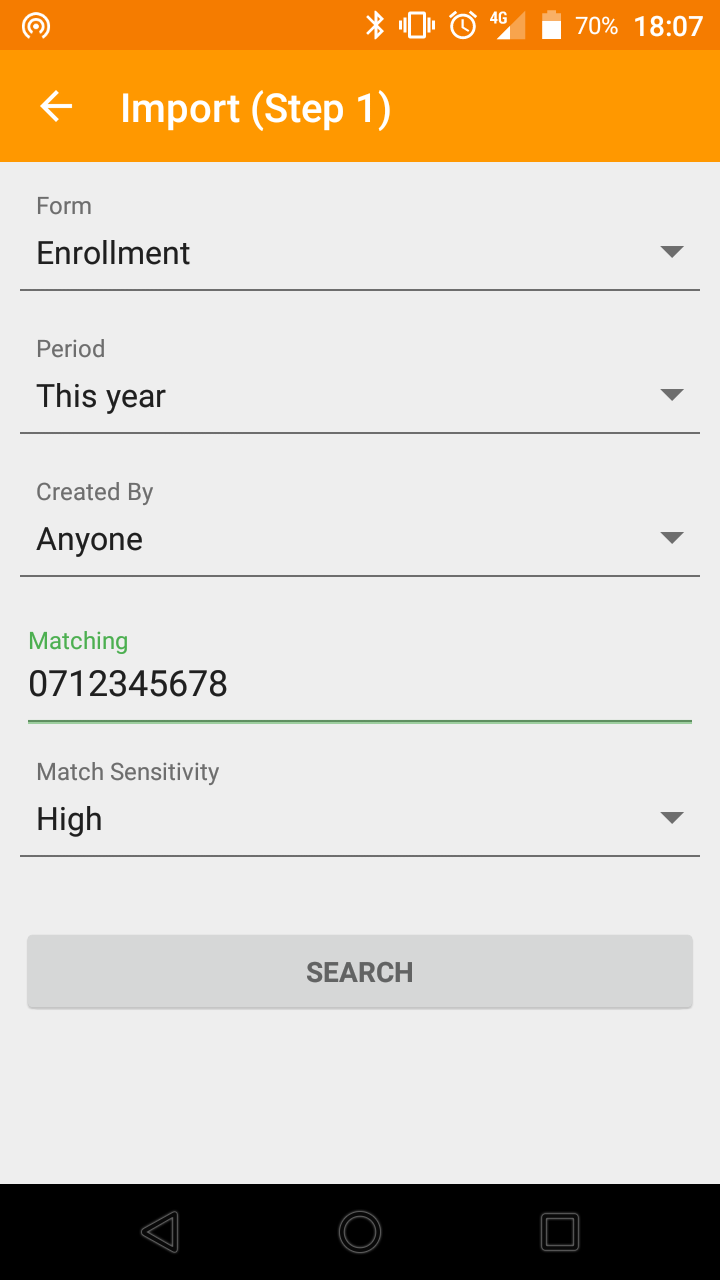
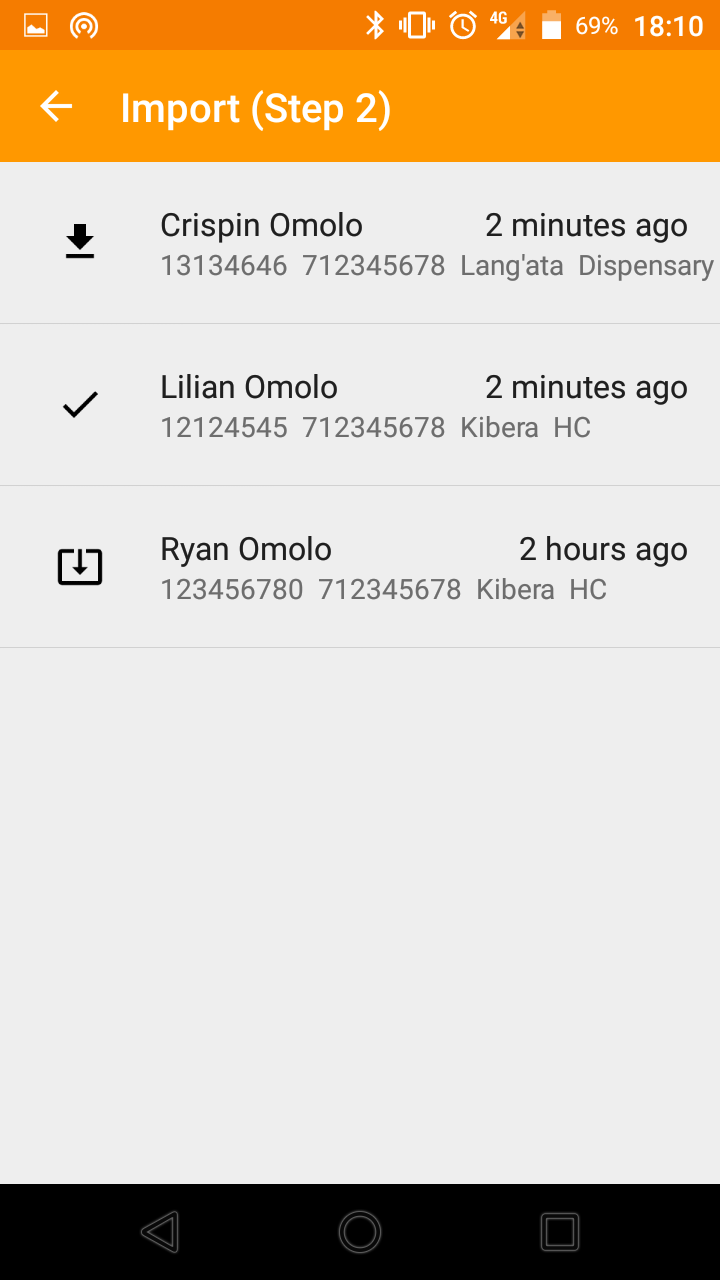
Figs 1, 2 & 3. The sequence of events when importing a record from the server. Note the additional identifiers listed against each record matching the Telephone Number 712 345 678.
In reality, what this means is that a participant P(1) enrolled by field worker F(1) at site S(1) using mobile device M(1) can easily and accurately be followed up by field worker F(i) at site S(i) using mobile device M(i) at any point in the future. This is the essence of distributed longitudinal data collection.
Assumptions
Obviously, this strategy assumes a reliable internet connection. In 2016, this is a far more realistic assumption than any of the others described above. To be sure, the connection needs only be reliable but not necessarily persistent. Sites with intermittent connectivity could feasibly import participant records in batches for offline follow-up, and then reconnect to the internet to upload the day’s or week’s work.
Auxiliary requirements
What about other needs such as sending appointment reminders via text messages etcetera?
We’ve thought about that too. Different projects will have different requirements of this kind, so it not viable to implement them in a general purpose platform like Hoji. Instead, we provide a simple API that enables projects to develop their own custom solutions for their custom requirements while integrating with Hoji for the more complex case-tracking functionality.
Other possible forms of integration might include transmitting data collected on Hoji to third party applications such as the DHIS, data warehouses or even EMRs. For projects that do not have the time or expertise to build their own integration solutions, Hoji is able to do help develop the necessary middle-ware for them.
We hope that through this innovation and the continuous improvement that is sure to follow, more organizations will join us in our overarching mission to help collect better quality data more efficiently. You’re welcome to contact us any time for a live demo. Have a great week!
Hello, this weekend is fastidious in favor off me, as
this pkint in time i am reading this enormous educational article
here at my home.