“Originals are always honored over duplicates.” – Edmond Mbiaka
You’re collecting data from health facilities, say. So you send out enumerators to the field. You expect one entry per facility. But you and I know that mistakes happen. So out of the 500 records you receive, 10 are duplicates. Not the end of the world, but annoying.
At worst, duplicates mean misleading results – if you neglect to clean them out. At best, it’s extra work you have to do to identify and remove them.

Naturally, we at Hoji don’t like that very much. After all, our principal commitment is to help development organizations close the gap between data gathering and decision making. We work hard every day to eliminate all the tinkering that delays decisions, action and ultimately undermines the impact of your programs. We think less about solving data problems and more about preventing them from happening in the first place.
Our solution? Don’t even let those pesky duplicates make it to your dataset!
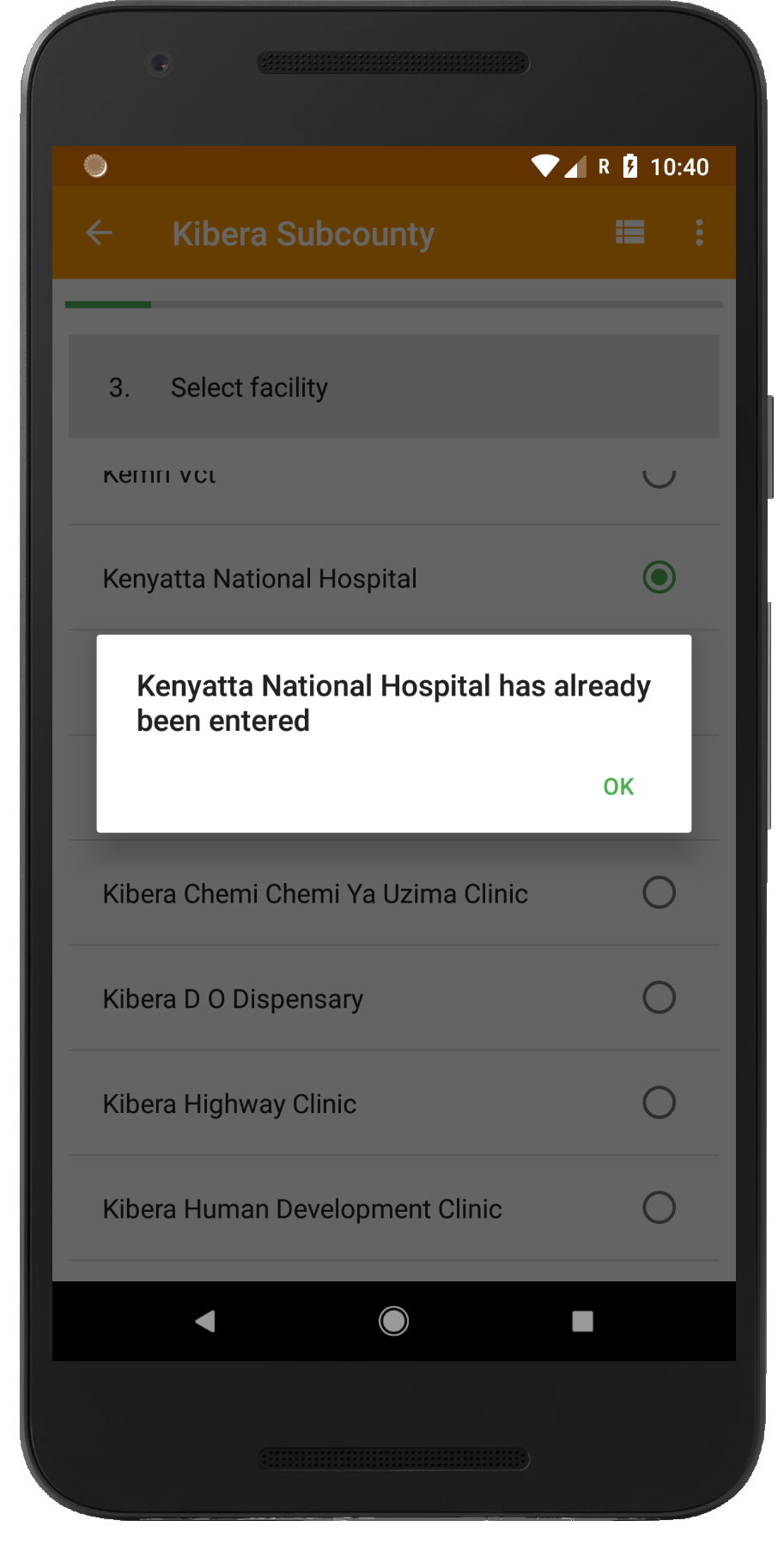
With the recently released version of Hoji (8.2.3), you can now designate a particular variable in your data collection form as unique. What that does is ensure that an enumerator cannot enter the same value for that variable more than once. It’s really that simple, but the implications are important.
It means that as long as your data set has a naturally unique attribute, such as the MFL Code for health facilities in Kenya or an individual respondent’s telephone number or National ID, you can readily take advantage of this feature.
Field-based data management is complex, and fraught with many challenges. But this is not an excuse for dirty data. The very point of digital data collection is to take full advantage of modern computing power to weed out every cause of dirty data that could possibly be prevented. From enforcing range-checks to mandatory branching logic – and now duplicate prevention, we are committed to delivering the highest quality data to power development programs.
I work with a research based organization in Kenya where we collect a good a mount of data using ODK. One of our biggest challenge is duplicate entries by enumerators. The respondents we interview have been assigned unique identifiers and they are surveyed continuously for a period of 12 month which is split into quarters. All the respondents need to be interviewed at 3 times within the 12 months.
My question is how do you code this during survey development to restrict the enumerators from making double entries.
Thanks for the support.
Gabriel, is that a longitudinal study you are doing? Hoji has 2 solutions for a problem like this. For one-off cross-sectional surveys, the solution described in this post works best to prevent duplicate data. You simply designate one variable (in this case your identifier) as unique, and Hoji ensures that only one copy of the identifier can be entered.
For longitudinal surveys like what you have described, the best solution is to create a baseline-vs-routine-data relationship. The way this works is that you create one baseline/enrollment record and then, over time, attach routine/visit data to that one baseline record. This way, everything associated with one respondent can be linked together reliably without duplication. Hoji allows you to import the baseline record to any device at any time so that follow-up is easy and flexible. You can read more about this here.
As far as I know this functionality is not available in ODK or any of the other popular data collection platforms. If this sounds interesting to you, we’d be happy to show you a demo. Ahsante.
Great stuff
This is the way to go.. Kudos Gitahi Ng’ang’a and team
Glad you enjoyed reading, Moses!
Thanks hoji team for the update.I have Learnt a lot from that end.am a data enthusiast.
Nice read, indeed hoji is offering an efficient solution to data collection challenges. Keep up the good work.